Chinese Character Calligraphy Recognition with Intra-class Variant Clustering

The goal of this project is to recognise the 100 most commonly used chinese characters, written in calligraphy in the semi-cursive script. As compared to handwritten chinese characters, chinese calligraphy characters are harder to recognise, even for trained experts because they can be written in a less restrictive way to express the author’s personality and emotions.
Background
Chinese Script
Chinese script consists of around 70,000 characters. The first 3775 most frequently used characters covers 99.65% of the usage, so a lot research related to chinese character recognition only consider the 3775 characters. In this project, I will only target the 100 most commonly used characters as calligraphy data of rare characters are scarce.
Each character is made of “sub-characters”, also known as radicals.



Chinese calligraphy can be categorised into 5 styles, namely seal, clerical, regular, semi-cursive and cursive. They are different in terms of their stroke properties, local structure, or even global structure. Hence, it is challenging to build one classifier to recognise characters of all styles.

Seal

Clerical

Regular

Semi-cursive

Cursive
Challenges
Intrinsic similarities among characters make it hard to differentiate between them.
A character also can have more than one variations. Some of the variants have totally different structure. This is because chinese calligrapher uses simplified chinese and traditional chinese characters interchangeable, and also because of the less restrictive nature of the semi-cursive script.






Possible Approaches
Two-Step Approach
In recent years, great success has been achieved in the area of handwritten chinese character recognition (HCCR). Since the main difference between these two types of characters are the stroke properties, one approach is to break the problem down into two steps - first extract the skeleton of the character, then treat it as a HCCR problem. However, skeletonisation requires the character image to have clear and well-separated strokes, so the skeleton information might not be able to be accurately extracted in some cases. Besides, the stroke placement between handwritten and calligraphy characters might differ as calligraphy characters usually adhere more closely to a certain aesthetic standard.

Calligraphy input

Skeletonised character
HCCR output
HCCR Approaches
Since our problem is similar to HCCR, we can also consider approaches that have been successfully applied in HCCR. These approaches can be categorised into character-based, radical-based and stroke-based.
In character-based approaches, each character is treated as one class. State-of-the-art results have been achieved using convolutional neural networks (CNNs) given sufficient data. However, they cannot handle characters that are not in the training data, this is known as the zero-shot problem.
Next, both radical-based and stroke-based methods decompose the character into smaller units. They can be treated as an image captioning problem, and can address the zero-shot problem, which are very useful because of the large chinese character set.
All three types of methods employ a model with an encoder-decoder architecture, where the encoder will extract the image features. In character-based approaches, the decoder can directly decode the feature to it’s class; In radical-based and stroke-based approaches, the decoder is more complex as it has to decode the features into a sequence of radicals or strokes. Since there are limited data to train the model, I will be using a simpler model with a character-based approach in this project.
Traditional character-based approaches involve the extraction of hand-crafted features. This imposes limitations on the model performance due to the low-level feature representation.
General steps in traditional methods: -
- Hand-crafted feature extraction
- Dimensionality reduction
- Classifier (eg. SVM) training
Recent work on character recognition mostly involves the use of CNNs as they are able to extract more complex features from images, thus having much better performance.
Methodology
I attempt to overcome the dataset limitations and address the intra-class variant issue by paying great attention on the data preparation steps. New training data will be synthesised while ensuring the representativeness in the dataset. This is done by carrying out clustering within each class to identify the variants first, then perform the train-valid-test-split and data augmentation based on the clustering results. Then, a CNN classifier is trained via transfer learning for character recognition.
Dataset
Since I couldn’t find any suitable open dataset for this project, I have scraped the data from an online chinese calligraphy dictionary (www.shufadict.com) under the semi-cursive script category. Each image have been segmented and labelled as a single character.
The final dataset contains 10035 images for 100 characters. Based on the histogram of class size, there is a class imbalance problem and will be addressed in the pre-modelling steps.
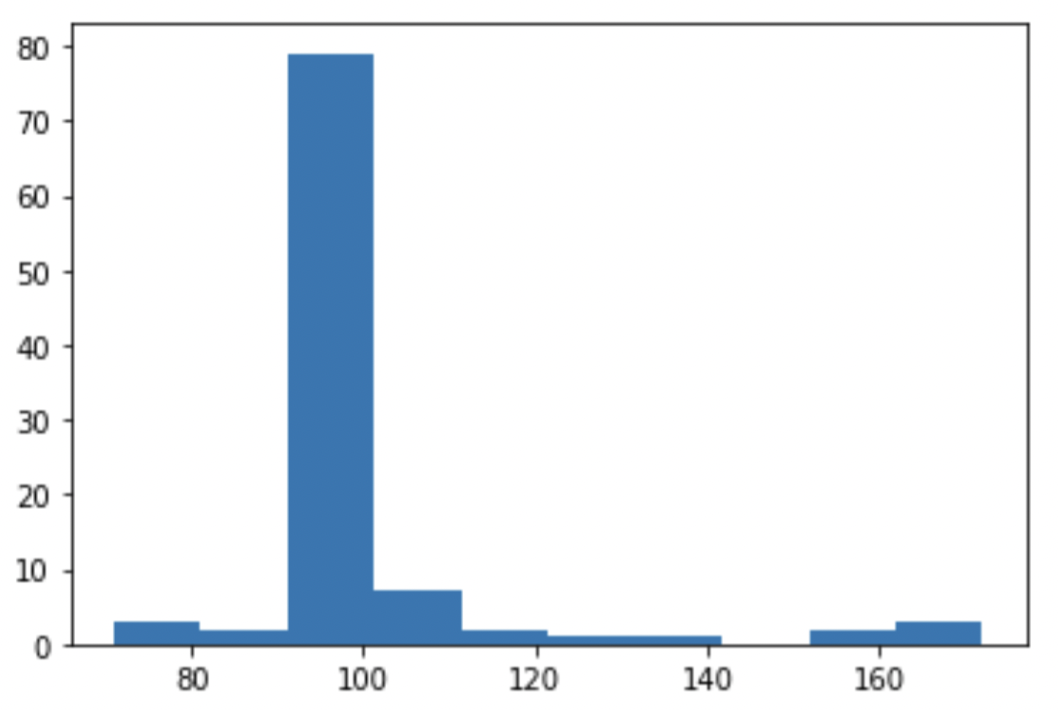
Image preprocessing
[source code]




Some images with poor image quality have to be enhanced manually to fix the segmentation failures.
Data preparation
[source code]
Intra-class Variant Clustering
Variants can be loosely defined as characters that belong to the same class but have different global structure.
After skimming through the dataset, I found out that there is an intra-class imbalance issue. For example, the character “一” has two variants, one of them make up around 81% of the data in the class. The dataset has to be handled with extra care to ensure each of the train validation and test set covers all the variations. Hence, I first cluster images from the same class with the same spatial layout together to identify the variants.
Feature selection
Clustering requires features to be extracted from the images. A few image descriptors that are widely used in computer vision tasks are considered: -
- Histogram of gradient (HoG)
- Perceptual hashing (pHash)
- GIST
We would want to select the feature that can minimise distance between similar images and maximize distance between variants in order to obtained well-separated clusters. To compare the descriptors, L2 distance between a few hand-picked clusters (a group of 4 similar images) are estimated based on the mean feature extracted using different descriptors.
Steps for distance estimation: -
- Manually group 4 similar images of the same character together
- Compute feature vector for each image using the selected descriptor
- Average the set of feature vectors for each cluster
- Compute the L2 distance between the mean feature of two clusters
| HoG | pHash | GIST | ||
|---|---|---|---|---|
| 于 |
distsimilar (
 ,
,
 )
)
|
0.30 | 303.03 | 137.75 |
distvariant (
,
 )
)
|
0.51 | 392.81 | 167.25 | |
| Score | 1.71 | 1.30 | 1.21 | |
| 时 |
distsimilar (
 ,
,
 )
)
|
0.36 | 330.73 | 180.75 |
distvariant (
,
 )
)
|
0.62 | 444.32 | 200.00 | |
| Score | 1.72 | 1.34 | 1.11 |
Distance estimated between clusters
* Score = distvariant ÷ distsimilar
GIST gives the highest score for both characters, so GIST features will be extracted for the clustering task.
GIST feature
The GIST feature is extracted using a bank of 20 Gabor filters of different scale and orientation with the following steps: -
- Split image into 4x4 non-overlapping blocks
- Convolve each block with one of the Gabor filters
- Take the average activation output of each block
The output values are combined together to form the feature vector. Each Gabor filter results in 16 features, so we have a final feature vector of dimension 16 x 20 = 320.



Clustering
The data points are clustered using k-means with L2 distance as the distance metric.
Within each character class, I have run it with k=2 and k=3, the number that gives the highest silhouette score is chosen. If none of the silhouette scores don’t exceed a certain threshold, then the class will remain to have one cluster.
In the splitted data, 21 classes are identified with 2 variants and only 1 class has 3 variants. The figure below indicates that there is an intraclass imbalance issue for some characters.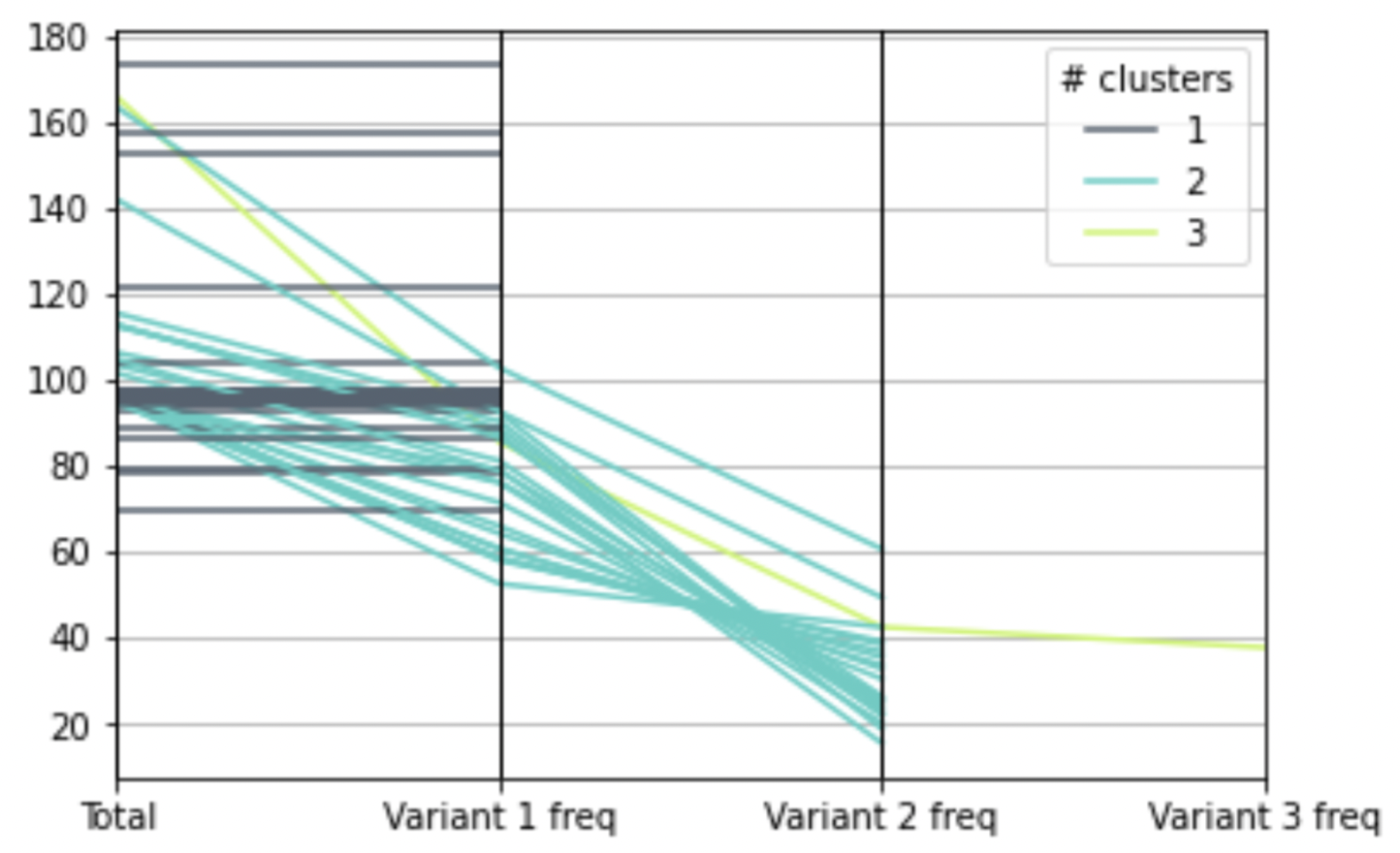
 Silhouette score = 0.3375, k = 3
Silhouette score = 0.3375, k = 3
 Silhouette score = 0.2648, k = 2
Silhouette score = 0.2648, k = 2
Images in the circled region belong to the wrong cluster
Since the purpose of variant clustering is to ensure each variant has roughly equal size, some minor errors are still acceptable at this stage.
Train-Valid-Test-Split
The dataset is split based on a ratio of roughly 6:2:2. For the classes that have more than one clusters, the data is sampled such that the number of data points for each variants in the validation and test set are balanced to ensure they cover all the variations.
New training data are synthesised through data augmentation. More samples are generated for the minority classes and minority variants to balance the data size.
| Number of data points | ||
|---|---|---|
| Dataset | Before augmentation | After augmentation |
| Train | 8035 | 15856 |
| Validation | 2000 | 2000 |
| Test | 2000 | 2000 |
| Total | 12035 | 19856 |
Dataset size



This completes our data preparation step.
Model
[source code]
Model Architecture
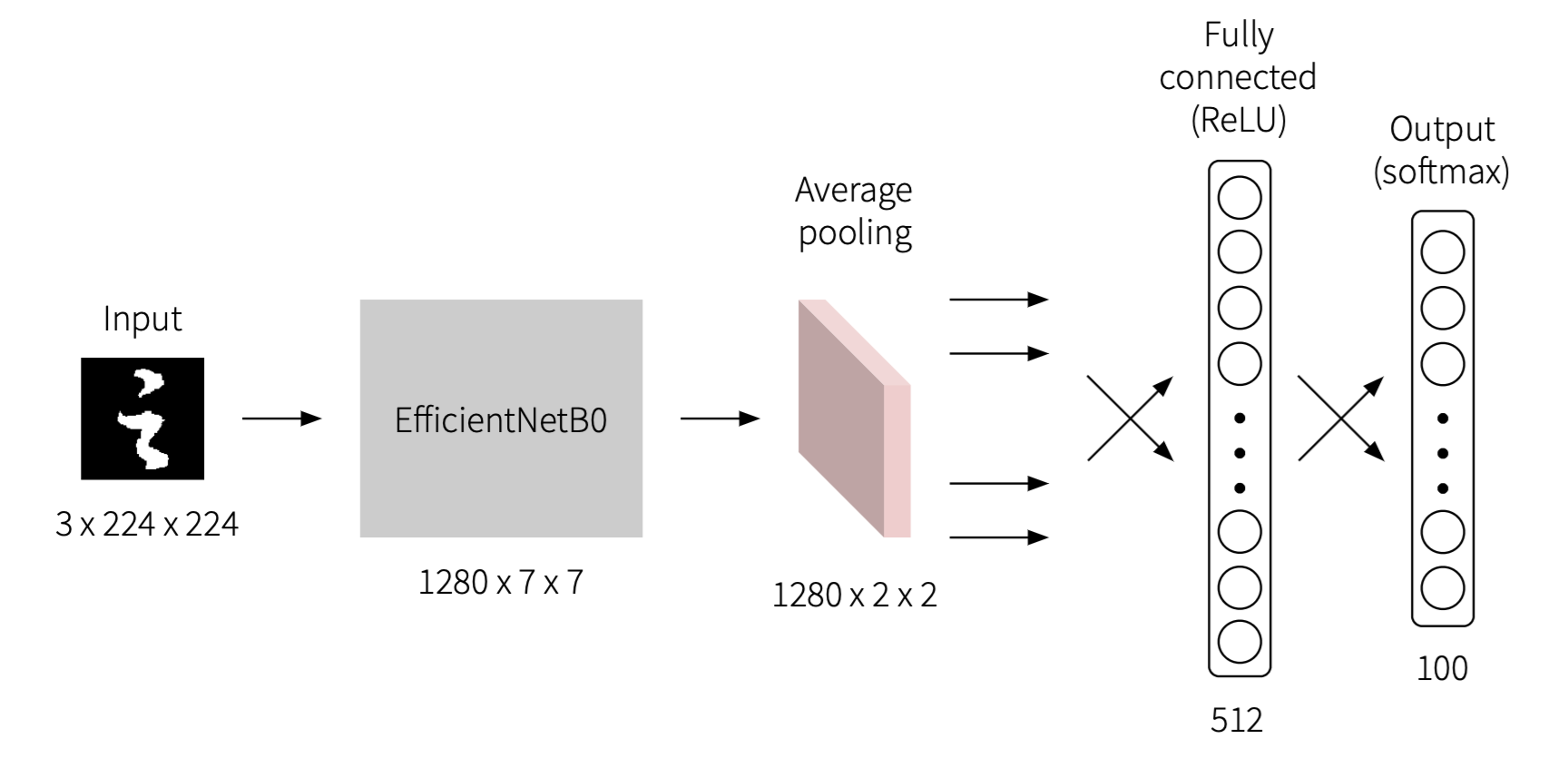
I have selected EfficientNet with pre-trained weights without the classification layers as the base of my model. EfficientNet has managed to achieve good accuracy on image classification on ImageNet. The base model, EfficientNetB0, is used to get a lighter-weight network.
An average pooling layer is used to downsample the feature maps obtained from EfficientNet to reduce the parameters of the model.
Model Optimisation
As for the model optimisation, cross-entropy is used as the loss function. I have used mini-batch gradient descent with batch size of 16 and Adam optimizer. The batch size and optimizer are selected by doing a grid search.
I found out that an initial learning rate of 0.0005 works best, and it is reduced by a factor of 0.5 when the validation accuracy doesn’t improve for 2 epochs.
Result and Discussion
The model is able to achieve top-1 accuracy of 91.65% and top-3 accuracy of 97.5% on the test set.
Failure in variant detection
To investigate the reasons why the model failed to classify the images, I first looked into the worst performing class ("只"). I found out that the algorithm has failed to detect all variants. Since some of the minority variants did not get grouped into an independent cluster, they remain to have fewer data points after augmenting the data. Hence, the model failed to learn from the minority variants due to the lack of training samples.




Similar characters
Some of the misclassified samples got predicted as another character with similar appearance.
Misclassified samples
 然
然
 最
最
 意
意
 来
来
Samples from predicted class
 就
就
 家
家
 一
一
 成
成
Poor quality images
In some images, the strokes are unclear and are fused together. These poor quality images are harder to classify, and can disturb the training of the model. This can be potentially improved by paying more attention to the data preprocessing steps, such as applying stronger erosion in the data augmentation step to train the model to classify characters under poor conditions








Conclusion and Future Work
In this post, I have explained the steps to perform k-means clustering with GIST feature to improve the representativeness in our training, validation and test set. Then, I have used transfer learning with EfficientNet to train a classifier to recognise the chinese challigraphy characters.
Based on the analysis of the results, most problems encountered with the model can be improved by having a larger dataset, so the future work includes collecting more data to expand the dataset.
Besides that, we could also experiment with few-shot learning to train classifiers that can recognise more characters. Since handwritten chinese characters are easier to collect, we can use them as our support set to boost the model performance.
The project repo can be found here. Thanks for reading!